Deep Dive into etcd and Kubernetes
This workshop provides an in-depth exploration of etcd and its critical role in Kubernetes. Participants will gain a comprehensive understanding of etcd, learn how to install and configure it, and practice essential tasks such as data manipulation, troubleshooting, performance tuning, and recovery.
Deep Dive into etcd and Kubernetes
Workshop Overview
This workshop provides an in-depth exploration of etcd and its critical role in Kubernetes. Participants will gain a comprehensive understanding of etcd, learn how to install and configure it, and practice essential tasks such as data manipulation, troubleshooting, performance tuning, and recovery.
Agenda
- Introduction to etcd
- How etcd Works
- According to GitHub
- Use Cases of etcd
- Installing etcd as a Binary
- Running etcd as a Container Using Docker
- Connecting to etcd
- Putting and Pulling Data from etcd
- Troubleshooting Common Issues
- Improving etcd Performance
- Backup and Restore from Snapshot
- Adding and Removing Members
- Manually Recovering from an Outage
- Setting Up Certificates for etcd
- API
- etcd Clustering
- Raft Consensus Algorithm
System Requirements
Before starting, ensure your system meets the following requirements:
- Operating System: Linux (Ubuntu 18.04 or later preferred)
- Memory: Minimum 2 GB RAM
- Storage: Minimum 20 GB free disk space
- CPU: 64-bit processor
- Network: Stable internet connection
- Tools: Docker, curl, wget
Introduction to etcd
What is etcd?
- etcd is a distributed, consistent key-value store for shared configuration and service discovery.
- It is written in Go and uses the Raft consensus algorithm to manage a highly-available replicated log. In Kubernetes, etcd stores all cluster data, including the state and configuration of all Kubernetes objects.
- The name etcd comes from the Unix directory
/etc, where configuration files are stored, and ’d’ for distributed.
How etcd Works
Key Concepts:
Raft Algorithm: Provides a distributed consensus algorithm for managing a replicated log.
Raft Consensus Algorithm: The official paper describing the algorithm.
Raft Visualization: A visualization tool for understanding Raft.
Consensus: etcd uses the Raft algorithm to ensure data consistency across multiple nodes.
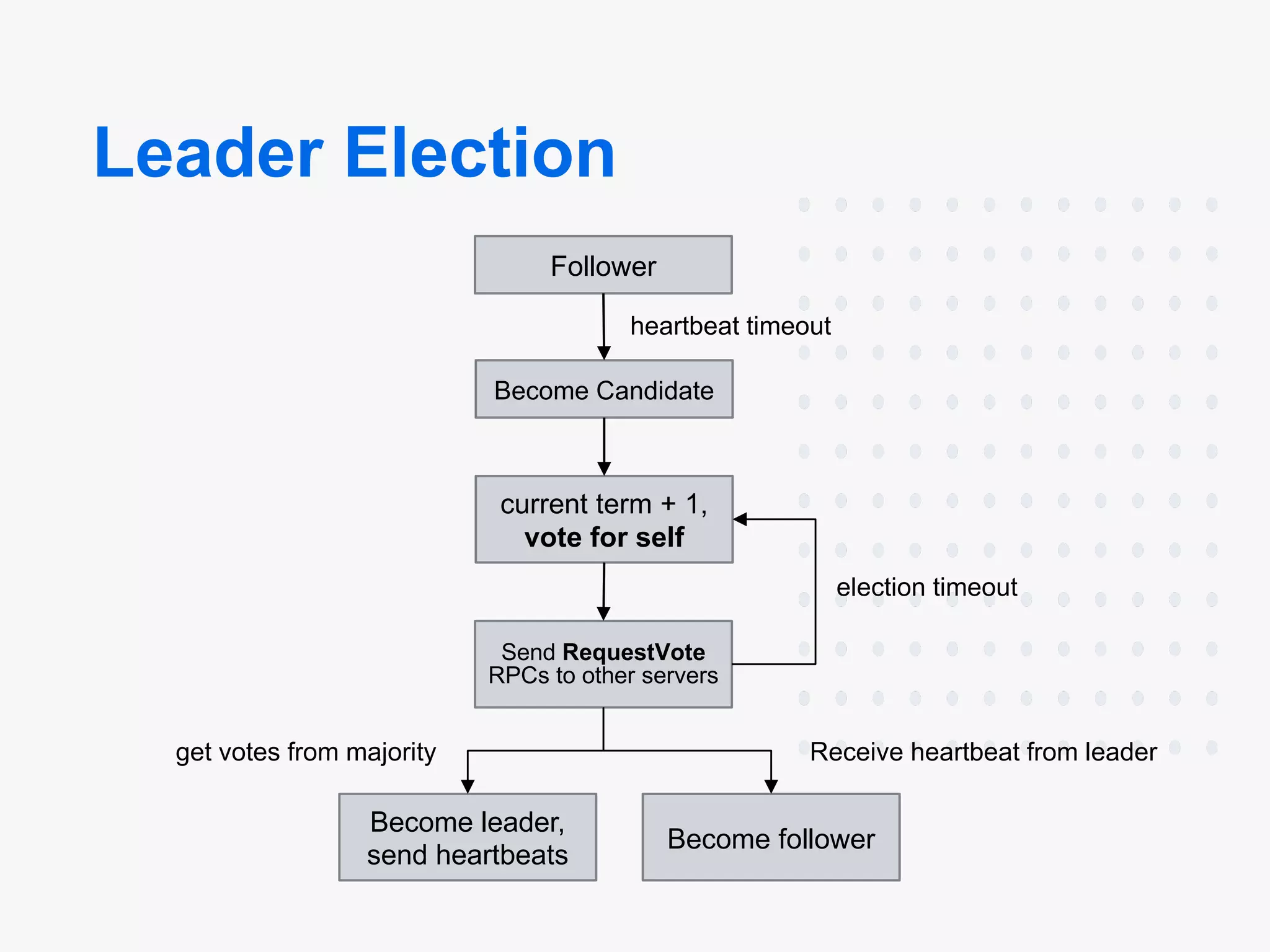
Leader Election: Determines which node is the leader for handling requests.
Log Replication: Ensures all nodes have the same data.
WAL (Write-Ahead Log): This ensures that data is not lost in a crash.
Snapshots: Periodically created to provide a point-in-time copy of data.
Diagrams:
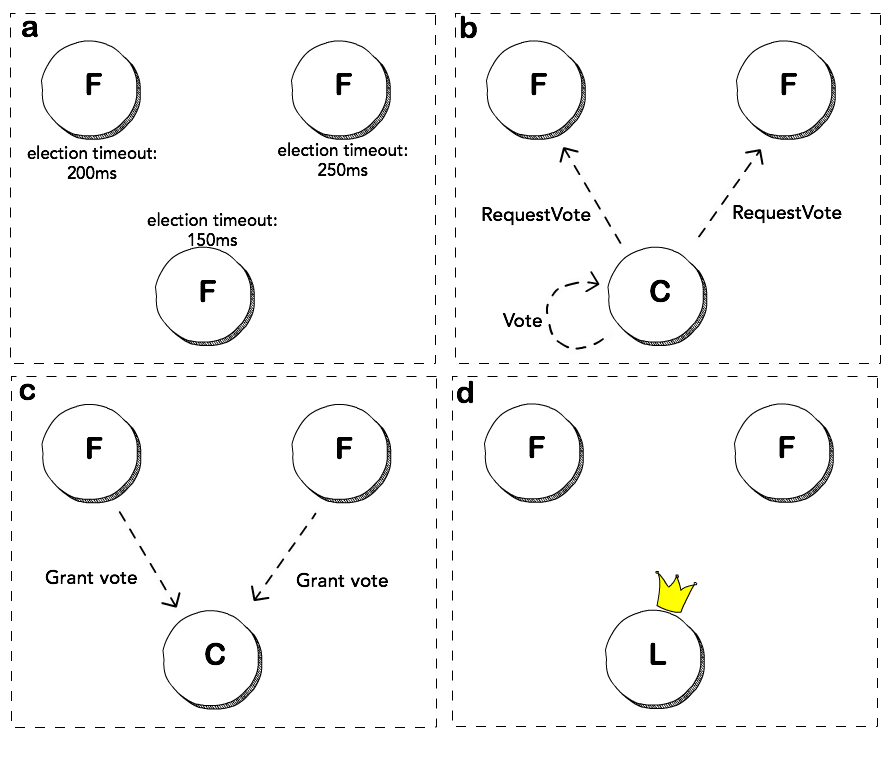
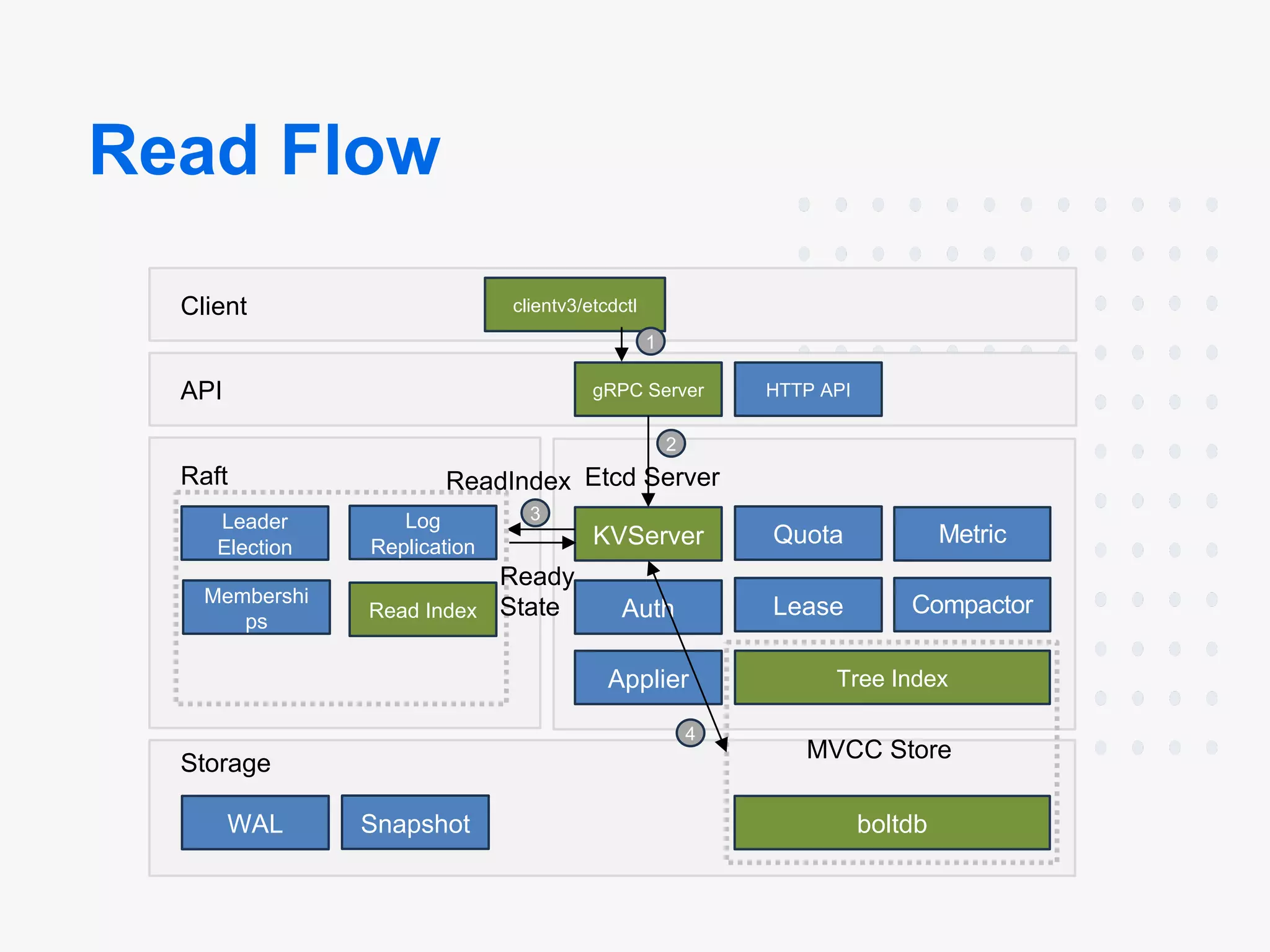
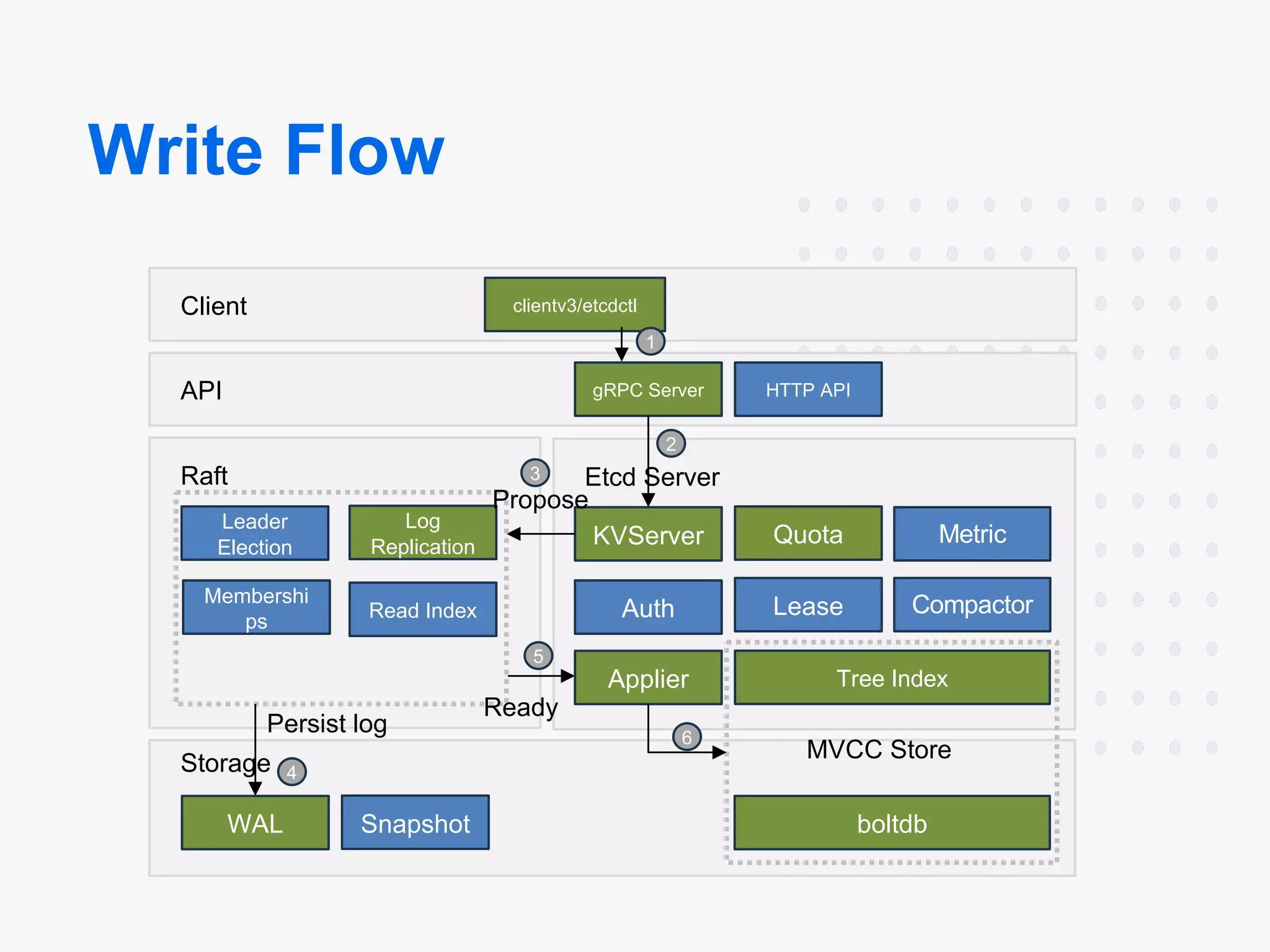
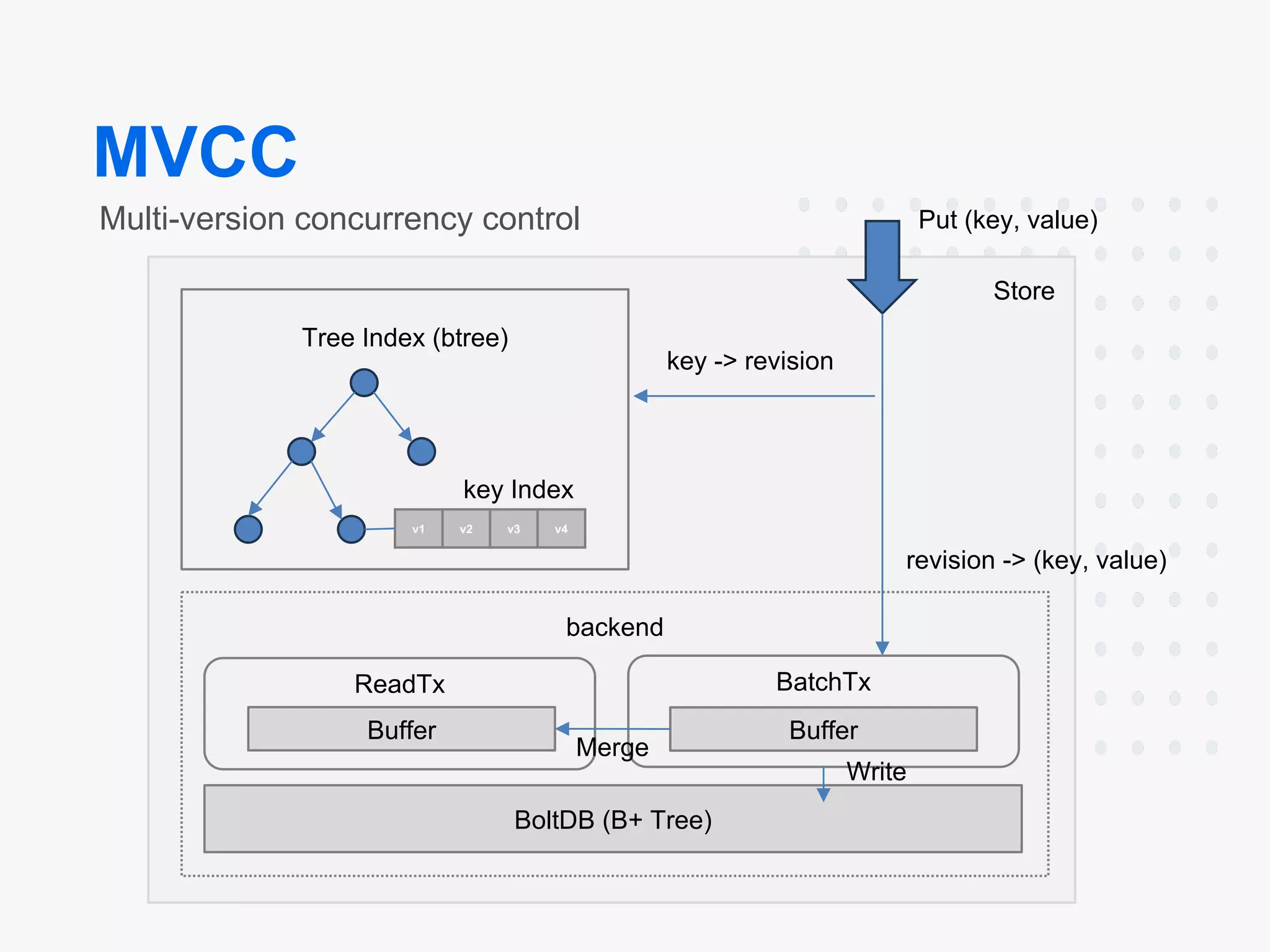
Architecture:
- Components: etcd consists of multiple components that can be broken down into Client, API, Raft, Etcd Server, Storage, MVCC Store
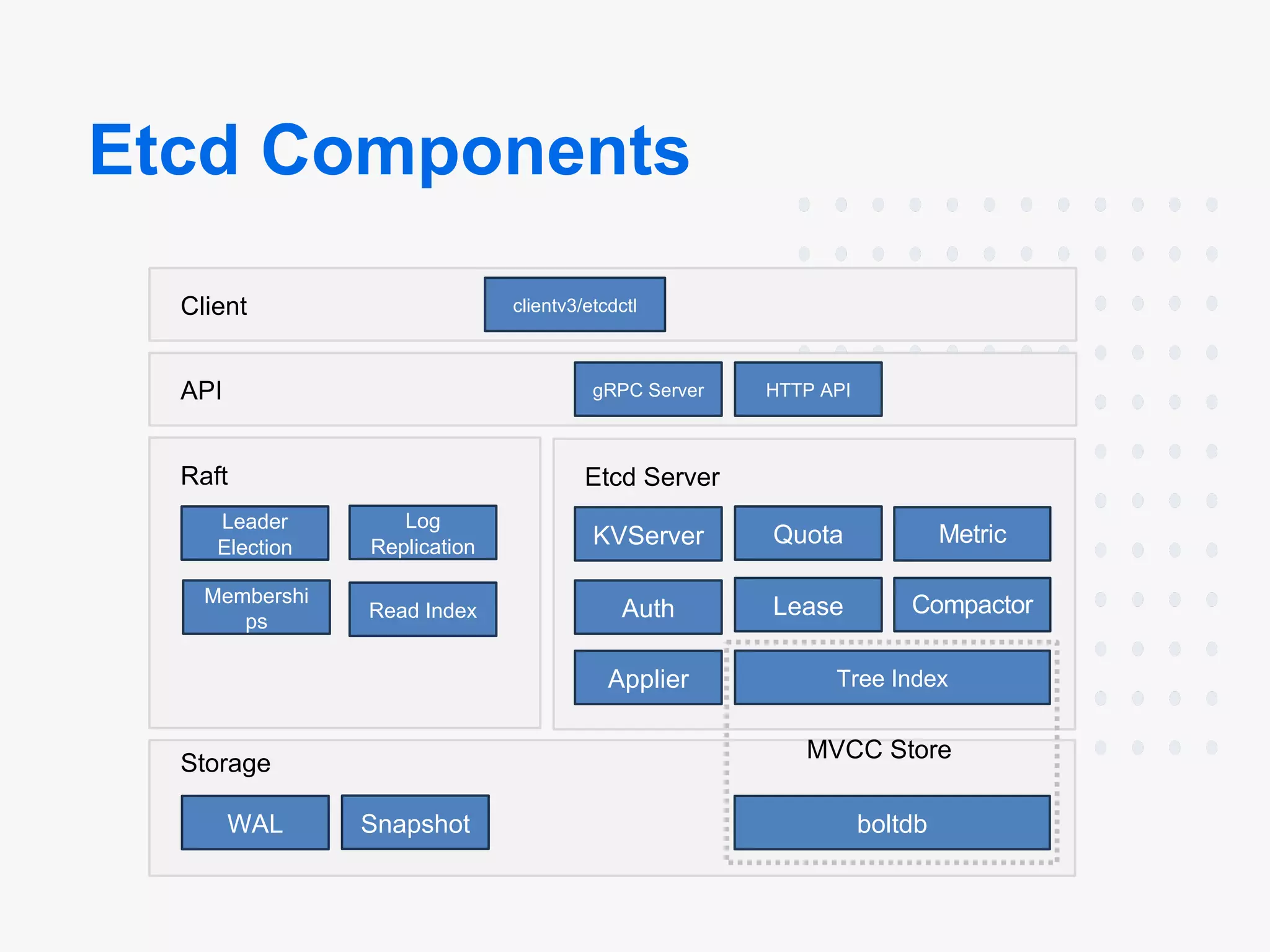
- Leader-Follower: etcd runs on each machine in a cluster and handles leader election during network partitions and the loss of the current leader using the Raft consensus algorithm.
- High Availability: Communication between etcd machines is handled via the Raft consensus algorithm.
Consensus Algorithm:
- Safety: Ensures they will never return an incorrect result.
- Availability: Fully functional as long as the majority of servers are running.
- Efficiency: Commands can be completed as soon as most of the cluster has responded.
According to GitHub
etcd is a distributed reliable key-value store for the most critical data of a distributed system, with a focus on being:
- Simple: Well-defined, user-facing API (gRPC)
- Secure: Automatic TLS with optional client cert authentication
- Fast: Benchmarked 10,000 writes/sec - benchmarks
- Reliable: Properly distributed using the Raft algorithm
Use Cases of etcd
etcd is used in a variety of applications for different purposes:
- Service Discovery: Automatically detects services in a network.
- Storing DB Connections: Keeps database connection strings secure and consistent.
- Cache Settings: Stores and retrieves cache settings efficiently.
- Feature Flags: Manages feature flags in applications.
Present in:
- Kubernetes
- Traefik
- CoreDNS
- OpenStack
- Skydive
Installing etcd as a Binary
Step-by-Step Guide:
- Download the latest etcd release from the official GitHub repository.
wget https://github.com/etcd-io/etcd/releases/download/v3.4.15/etcd-v3.4.15-linux-amd64.tar.gz
tar xvf etcd-v3.4.15-linux-amd64.tar.gz
cd etcd-v3.4.15-linux-amd64
- Move the binaries to
/usr/local/bin.
sudo mv etcd etcdctl /usr/local/bin/
- Verify the installation.
etcd --version
etcdctl --version
Running etcd as a Container Using Docker
Step-by-Step Guide:
- Pull the etcd Docker image.
docker pull quay.io/coreos/etcd:v3.4.15
- Run etcd as a Docker container.
docker run -d \
-p 2379:2379 \
-p 2380:2380 \
--name etcd \
quay.io/coreos/etcd:v3.4.15 \
/usr/local/bin/etcd \
--name s1 \
--data-dir /etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://0.0.0.0:2379
- Verify the container is running.
docker ps
Connecting to etcd
Using etcdctl:
- Set environment variables for easier access.
export ETCDCTL_API=3
export ETCDCTL_ENDPOINTS=http://localhost:2379
- Verify connection.
etcdctl endpoint health
Putting and Pulling Data from etcd
Put Data:
etcdctl put foo "Hello, etcd"
Get Data:
etcdctl get foo
Output:
foo
Hello, etcd
Pulling Kubernetes Secrets from etcd:
To pull Kubernetes secrets from etcd, you need to base64 decode the values stored in etcd. Here is an example of how to retrieve a Kubernetes secret:
- Retrieve the secret:
etcdctl get /registry/secrets/default/mysecret
Output:
/registry/secrets/default/mysecret
{"kind
":"Secret","apiVersion":"v1","metadata":{"name":"mysecret","namespace":"default","..."},"data":{"username":"dXNlcm5hbWU=","password":"cGFzc3dvcmQ="}}
- Decode the secret values:
echo "dXNlcm5hbWU=" | base64 --decode
Output:
username
echo "cGFzc3dvcmQ=" | base64 --decode
Output:
password
Troubleshooting Common Issues
Common Issues and Solutions:
- Cluster Unavailability:
etcdctl endpoint status --write-out=table
- Network Issues: Ensure ports 2379 and 2380 are open.
- Data Corruption: Check logs for
etcdandetcdctl.
Improving etcd Performance
Optimization Tips:
- Use SSDs for storage.
- Increase available memory.
- Tune etcd configurations (e.g.,
--snapshot-count).
Example Configuration:
etcd --name s1 \
--data-dir /etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://0.0.0.0:2379 \
--snapshot-count 10000
Backup and Restore from Snapshot
Backup:
etcdctl snapshot save backup.db
Restore:
etcdctl snapshot restore backup.db \
--name s1 \
--data-dir /var/lib/etcd \
--initial-cluster s1=http://localhost:2380 \
--initial-cluster-token etcd-cluster-1
Adding and Removing Members
Add Member:
etcdctl member add s2 http://<new-member-ip>:2380
Remove Member:
etcdctl member remove <member-id>
Check Member List:
etcdctl member list
Manually Recovering from an Outage
Steps to Recover:
- Identify the latest snapshot and WAL files.
- Restore from a snapshot if necessary.
etcdctl snapshot restore <snapshot-file>
- Restart, etcd, with restored data.
Example Commands:
systemctl stop etcd
etcdctl snapshot restore backup.db --data-dir /var/lib/etcd
systemctl start etcd
Setting Up Certificates for etcd
Certificates are used to secure communication between etcd nodes and clients. Here are the steps to set up certificates:
- Generate CA Certificate:
openssl genrsa -out ca.key 2048
openssl req -x509 -new -nodes -key ca.key -subj "/CN=etcd-ca" -days 10000 -out ca.crt
- Generate Server Certificate:
openssl genrsa -out server.key 2048
openssl req -new -key server.key -subj "/CN=<your-etcd-server-ip>" -out server.csr
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt -days 365
- Generate Client Certificate:
openssl genrsa -out client.key 2048
openssl req -new -key client.key -subj "/CN=etcd-client" -out client.csr
openssl x509 -req -in client.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out client.crt -days 365
- Configure etcd to Use Certificates:
etcd --name s1 \
--data-dir /etcd-data \
--listen-client-urls https://0.0.0.0:2379 \
--advertise-client-urls https://0.0.0.0:2379 \
--cert-file=server.crt \
--key-file=server.key \
--client-cert-auth \
--trusted-ca-file=ca.crt \
--peer-cert-file=server.crt \
--peer-key-file=server.key \
--peer-client-cert-auth \
--peer-trusted-ca-file=ca.crt
API
- HTTP-based
- etcdctl
- HTTP client (curl, wget, postman…)
etcd Write
Set a key message with the value Hello can be done as:
$ etcdctl set /message Hello
Hello
or
$ curl --cacert ca.crt --cert client.crt --key client.key -X PUT http://127.0.0.1:2379/v2/keys/message -d value="Hello"
{
"action": "set",
"node": {
"key": "/message",
"value": "Hello",
"modifiedIndex": 4,
"createdIndex": 4
}
}
etcd Read
Read the value of the message back:
$ etcdctl get /message
Hello
or
$ curl --cacert ca.crt --cert client.crt --key client.key http://127.0.0.1:2379/v2/keys/message
{
"action": "get",
"node": {
"key": "/message",
"value": "Hello",
"modifiedIndex": 4,
"createdIndex": 4
}
}
etcd Delete
etcdctl rm /message
or
$ curl --cacert ca.crt --cert client.crt --key client.key -X DELETE http://127.0.0.1:2379/v2/keys/message
{
"action": "delete",
"node": {
"key": "/message",
"modifiedIndex": 19,
"createdIndex": 4
}
}
TTL
$ curl --cacert ca.crt --cert client.crt --key client.key -X PUT http://127.0.0.1:2379/v2/keys/foo?ttl=20 -d value=bar
{
"action": "set",
"node": {
"key": "/foo",
"value": "bar",
"expiration": "2014-02-10T19:54:49.357382223Z",
"ttl": 20,
"modifiedIndex": 31,
"createdIndex" :31
}
}
$ curl --cacert ca.crt --cert client.crt --key client.key http://127.0.0.1:2379/v2/keys/foo
{
"errorCode": 100,
"message": "Key not found",
"cause": "/foo",
"index": 32
}
etcd Clustering
“Five” is a typical number of servers, which allows the system to tolerate two failures.
Configuration
# This config is meant to be consumed by the config transpiler, which will
# generate the corresponding Ignition config. Do not pass this config directly
# to instances of Container Linux.
etcd:
name: my-etcd-1
listen_client_urls: https://10.240.0.1:2379
advertise_client_urls: https://10.240.0.1:2379
listen_peer_urls: https://10.240.0.1:2380
initial_advertise_peer_urls: https://10.240.0.1:2380
initial_cluster: my-etcd-1=https://10.240.0.1:2380,my-etcd-2=https://10.240.0.2:2380,my-etcd-3=https://10.240.0.3:2380
initial_cluster_token: my-etcd-token
initial_cluster_state: new
Clustering
- Start with the initial cluster of nodes (minimum 3)
etcd ... --initial-cluster "instance1PeerURL,instance2PeerURL...instanceNPeerURL"
- Add node
# on any node in a cluster
etcdctl member add <name> <peerURL>
# e.g.:
ectdctl member add
etcd5 http://etcd5:2380
On new member
etcd ... (Configuration stuff) --initial-cluster "peersURLs,<new member peer URL>"
Raft Consensus Algorithm
Strong Leader
Raft uses a more robust form of leadership than other consensus algorithms. For example, log entries only flow from the leader to different servers. This simplifies the management of the replicated log and makes Raft easier to understand.
Leader Election
Raft uses randomized timers to elect leaders. This adds only a tiny amount of mechanism to the heartbeats already required for any consensus algorithm,
while resolving conflicts simply and rapidly.
Membership Changes
Raft’s mechanism for changing the set of servers in the cluster uses a new joint consensus approach where the majority of two different configurations overlap during transitions. This allows the cluster to continue operating normally during configuration changes.
Terms in Raft
- Raft divides time into terms of arbitrary length.
- Terms are numbered with consecutive integers.
- Each term begins with an election, in which one or more candidates attempt to become leader.
Raft Flow
- Elect a distinguished leader
- Give the leader complete responsibility for managing the replicated log.
- The leader accepts the log entries from the clients. Replicates them on the other servers
Leader Election States
Each machine can be in one of the following states:
- Leader
- Follower
- Candidate
Raft Visualization
External Links
The following document was made using below resources:
- etcd.io
- Official etcd documentation
- Raft consensus algorithm paper
- Failure models
- etcd vs. other KV-stores
- etcd Clustering with Rancher
Conclusion
By the end of this workshop, participants should have a robust understanding of etcd’s role in Kubernetes, practical experience with its operations, and the skills to manage and troubleshoot etcd in production environments.