KubeVirt: Running VMs Natively in Kubernetes with Harvester Integration
KubeVirt is a powerful extension for Kubernetes that brings virtual machine management capabilities to the container orchestration platform. As more organizations adopt Kubernetes, hybrid workloads that combine traditional VMs and containerized applications become increasingly common. KubeVirt addresses this need by enabling VMs to run alongside containers in the same Kubernetes cluster. In this post, we’ll explore what KubeVirt is, why it’s needed for Harvester, how VMs are executed, where KVM fits into the picture, and provide practical YAML examples, virtctl CLI commands, and advanced scheduling techniques.
KubeVirt: You Got VM in My Pod
KubeVirt bridges the gap between containerized applications and traditional virtual machines by adding native support for VMs within a Kubernetes cluster. It allows users to manage VMs with the same Kubernetes APIs and workflows they use for containers, making it easier to integrate VMs into cloud-native environments.
Why KubeVirt?
Organizations that have adopted Kubernetes often face scenarios where certain applications must still run as VMs, whether due to legacy software dependencies, compliance requirements, or specialized workloads. KubeVirt allows these VMs to run natively within the Kubernetes ecosystem, enabling unified management across containers and VMs.
The Role of KubeVirt in Harvester
Harvester is an open-source Hyperconverged Infrastructure (HCI) solution built on top of Kubernetes, designed to manage both VMs and containerized workloads. With KubeVirt as a core component, Harvester supports VM operations natively within Kubernetes. This integration provides a unified interface for provisioning and managing VMs alongside containers, simplifying the infrastructure management process.

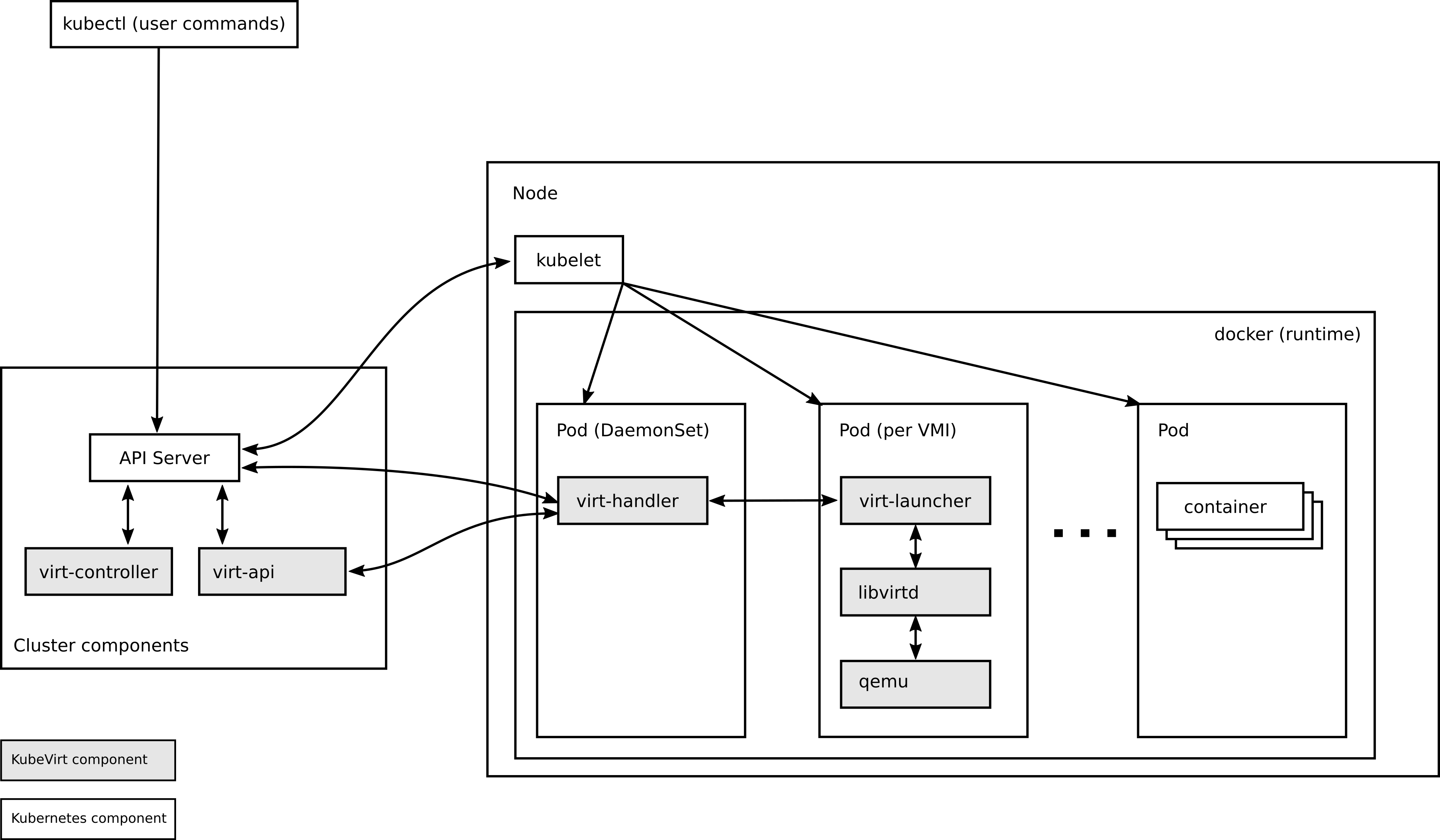
How KubeVirt Works
When you create a VM in KubeVirt, it is defined as a custom resource within the Kubernetes cluster, using a custom resource definition (CRD) specifically for VirtualMachineInstances (VMIs). The VM runs inside a Kubernetes pod, but instead of a containerized application, the pod contains a fully functional VM. Here’s a breakdown of how KubeVirt enables VMs to run in Kubernetes:
VM Definition: The VM is described using a custom Kubernetes resource that specifies details such as the CPU, memory, disk, and network configuration, similar to how pod specifications work.
Pod Creation for the VM: KubeVirt creates a pod that hosts the QEMU-KVM process, allowing the VM to execute as a guest operating system inside the pod.
QEMU-KVM Execution: The actual virtualization happens through QEMU, an open-source machine emulator and virtualizer, combined with KVM (Kernel-based Virtual Machine), which allows near-native performance by leveraging hardware-accelerated virtualization.
Resource Management: Kubernetes manages scheduling, resource allocation, and lifecycle events (start, stop, migrate) for the VM pods. KubeVirt handles the integration with the underlying KVM hypervisor.
Where KVM Fits In
KVM is a Linux-based hypervisor that enables virtualization by using hardware extensions like Intel VT-x or AMD-V. It plays a crucial role in KubeVirt, allowing VMs to run alongside containers in a Kubernetes environment. Here’s how KVM fits into the KubeVirt architecture:
- Kernel Integration: As part of the Linux kernel, KVM provides hardware-accelerated virtualization capabilities. It allows multiple VMs to run on a single physical machine, treating each VM as a separate process.
- User-Space Integration with QEMU: QEMU runs in user space to create and manage virtual machines. It leverages KVM for hardware acceleration, enabling VMs to achieve near-native performance.
- Resource Isolation: Each VM runs as a process in the Linux kernel, providing process-level isolation and security, similar to container-based workloads.
Example: KubeVirt Virtual Machine YAML
Here’s an example of a YAML definition for a KubeVirt virtual machine, demonstrating how to create a VM resource in Kubernetes:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: example-vm
namespace: default
labels:
app: example
spec:
runStrategy: RerunOnFailure
template:
metadata:
labels:
app: example
spec:
domain:
cpu:
cores: 2
memory:
guest: 4Gi
devices:
disks:
- name: rootdisk
disk:
bus: virtio
interfaces:
- name: default
bridge: {}
networks:
- name: default
pod: {}
volumes:
- name: rootdisk
containerDisk:
image: kubevirt/cirros-container-disk-demo
Explanation of the YAML
- runStrategy: Specifies the strategy for running the VM.
RerunOnFailurerestarts the VM if it crashes. - domain: Describes the virtual hardware, including CPU cores and memory allocated.
- devices: Lists the virtual devices attached to the VM, such as disks and network interfaces.
- volumes: Defines the storage volumes used by the VM. In this example, a container disk image is used.
- networks: Specifies the network configuration for the VM.
Using the KubeVirt CLI (virtctl) to Manage VMs
The virtctl command-line tool is used for managing KubeVirt resources, similar to how kubectl works for Kubernetes. Here are some common virtctl commands for managing VMs:
Starting a VM
To start a virtual machine:
virtctl start example-vm -n default
Stopping a VM
To stop a virtual machine:
virtctl stop example-vm -n default
Restarting a VM
To restart a virtual machine:
virtctl restart example-vm -n default
Pausing a VM
To pause a virtual machine:
virtctl pause example-vm -n default
Unpausing a VM
To unpause a virtual machine:
virtctl unpause example-vm -n default
Migrating a VM
To live-migrate a VM to another node:
virtctl migrate example-vm -n default
Viewing VM Console
To access the console of a VM:
virtctl console example-vm -n default
Listing VMs
To see the list of VMs in the cluster:
kubectl get vms -n default
These commands allow you to manage the entire lifecycle of a virtual machine from the command line, making it easier to integrate VM management into your Kubernetes workflows.
Node Balancing with Descheduler
In some cases, rebalancing the cluster based on current scheduling policies and load conditions is needed. The Descheduler can identify pods that violate scheduling policies and evict them. By default, KubeVirt VMs, treated as pods with local storage, won’t be evicted. To override this, add the following annotation:
spec:
template:
metadata:
annotations:
descheduler.alpha.kubernetes.io/evict: "true"
Using podAntiAffinity for Node and Zone Distribution
To ensure high availability and fault tolerance, you may want to spread VMs across different nodes or zones in the cluster. The podAntiAffinity configuration can achieve this by specifying that VMs with the same label should not run on the same node or within the same zone.
Example: podAntiAffinity to Distribute VMs Across Nodes
spec:
template:
metadata:
labels:
app: my-vm-app
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- my-vm-app
topologyKey: "kubernetes.io/hostname"
Example: Distributing Across Zones
spec:
template:
metadata:
labels:
app: my-vm-app
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- my-vm-app
topologyKey: "topology.kubernetes.io/zone"
Conclusion
KubeVirt is a crucial tool for integrating VMs into the Kubernetes ecosystem, making it easier to manage both traditional and cloud-native workloads. By leveraging KVM for virtualization, combined with advanced scheduling techniques like podAntiAffinity and Descheduler configurations, KubeVirt provides a seamless and unified experience for managing VMs alongside containers. The examples and commands provided offer a comprehensive approach to getting started with KubeVirt.